
TL;DR
Der problematischste Aspekt eines PSOD ist, dass Sie dadurch das Vertrauen in Ihre Infrastruktur verlieren. Solange Sie die Grundursache nicht lösen können, kann Sie der Gedanke, dass dies wieder oder auf einem anderen Server geschehen kann, Nachts wachhalten.
Verwenden Sie Runecast Analyzer, um zu prüfen, ob einer Ihrer Hosts von Bedingungen betroffen ist, die den VMware-purple screen of death verursachen können.
Was ist PSOD?
PSOD steht für Purple Screen of Diagnostics – oft auch als Purple Screen of Death bezeichnet: vom bekannteren Blue Screen of Death, der auf Microsoft Windows zu finden ist.
Dabei handelt es sich um einen Diagnosebildschirm, der von VMware ESXi angezeigt wird, wenn das Kernel einen schwerwiegenden Fehler entdeckt. Hier ist er entweder nicht in der Lage ist eine sichere Wiederherstellung durchzuführen oder die Ausführung nicht fortzusetzen, ohne ein viel höheres Risiko eines größeren Datenverlusts einzugehen.
Er zeigt den Speicherstatus zum Zeitpunkt des Absturzes sowie zusätzliche Details an, die für die Fehlerbehebung der Absturzursache wichtig sind: ESXi-Version und -Build, Ausnahme-Typ, Register-Dump, Backtrace, Server-Betriebszeit, Fehlermeldungen und Informationen über den Core-Dump (eine nach dem Fehler erzeugte Datei, die weitere Diagnoseinformationen enthält).
Dieser Bildschirm ist auf der Konsole des Servers sichtbar. Um ihn zu sehen, müssen Sie sich entweder im Rechenzentrum befinden und einen Monitor anschließen oder die Out-of-Band-Verwaltung des Servers (iLO, iDRAC, IMM… je nach Hersteller) verwenden.
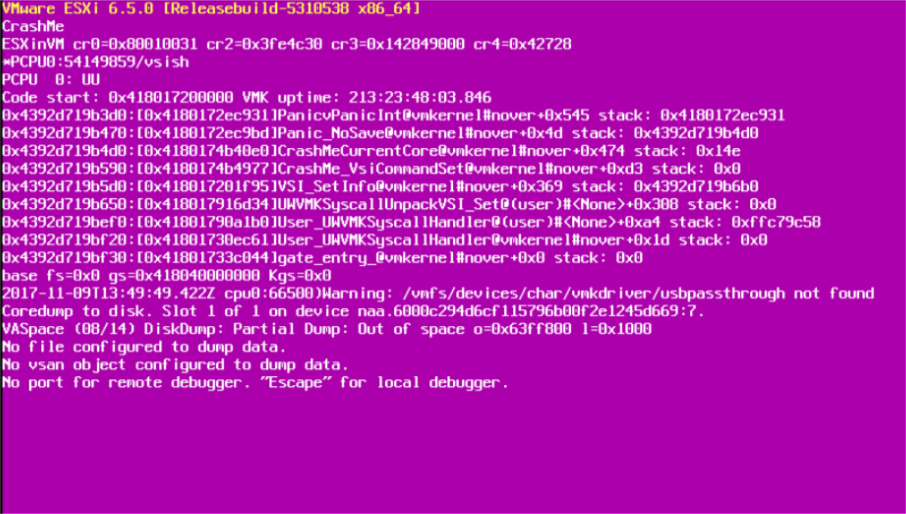
Wie kommt es zum PSOD?
Der PSOD ist eine Kernel-Panik. Obwohl es allgemein bekannt ist, dass ESXi nicht auf UNIX basiert, entspricht die Panic-Implementierung der UNIX-Definition. Der ESXi-Kernel (vmkernel) löst diese Sicherheitsmaßnahme als Reaktion auf ein Ereignis/einen Fehler aus, das/der nicht behebbar ist und bedeuten würde, dass eine Fortsetzung des Betriebs ein hohes Risiko für die Dienste und VMs darstellen würde.
Die häufigsten Ursachen für eine PSOD sind:
1. Hardware-Ausfälle, meist RAM- oder CPU-bezogen. Sie werfen normalerweise einen „MCE“- oder „NMI“-Fehler aus.
- „MCE“ (Machine Check Exception) ist ein Mechanismus ist ein Mechanismus innerhalb der CPU, um Hardware-Probleme zu erkennen und zu melden. In den Codes, die auf dem violetten Bildschirm angezeigt werden, gibt es wichtige Details zur Identifizierung der Ursache des Problems.
- „NMI“ – nicht maskierbare Unterbrechung, bei der es sich um eine Hardware-Unterbrechung handelt, die vom Prozessor nicht ignoriert werden kann. Da NMI eine sehr wichtige Meldung über einen HW-Fehler ist, besteht die Standardantwort ab ESXi 5.0 und folgende Versionen darin, eine PSOD auszulösen. Frühere Versionen protokollierten lediglich den Fehler und fuhren fort. Genau wie bei MCEs liefert der durch NMI verursachte violette Bildschirm wichtige Codes, die für die Fehlerbehebung entscheidend sind.
2. Software-Fehler
- unsachgemäße Interaktionen zwischen ESXi SW-Komponenten (z.B.: KB2105711)
- Rennbedingungen (z.B.: KB2136430)
- aus Ressourcen: Speicher, Heap, Puffer (z.B. KB2034111, KB2150280)
- Endlosschleife + Stapelüberlauf (z.B.: KB2105522)
- falsche oder nicht unterstützte Konfigurationsparameter (z.B.: KB2012125, KB2127997)
3. Sich falsch verhaltende Treiber; Fehler in Treibern, die versuchen, auf einen falschen Index oder eine nicht vorhandene Methode zuzugreifen (z.B.: KB2146526 , KB2148123)
WUSSTEN SIE?
Sie können zu Testzwecken, ein PSOD manuell auslösen.
Melden Sie sich über DCUI oder SSH mit einem privilegierten Konto beim ESXi-Host an
und starten Sie ihn:
vsish -e set /reliability/crashMe/Panic
Natürlich wird ein Testsystem empfohlen, idealerweise ein virtuell verschachtelter ESXi,
damit Sie die Konsole leicht beobachten können.
Informieren Sie sich aber vorab über die Folgen in unserem nächsten Abschnitt.
Was sind die Auswirkungen von PSOD?
Wenn die Panik auftritt und der Host abstürzt, werden alle darauf ausgeführten Dienste zusammen mit allen gehosteten virtuellen Maschinen beendet. Die VMs werden nicht anmutig heruntergefahren, sondern eher abrupt abgeschaltet. Wenn der Host Teil eines Clusters ist und Sie High Availablity (HA) konfiguriert haben, werden diese VMs auf den anderen Hosts im Cluster gestartet. Neben dem Ausfall und der Nichtverfügbarkeit der VMs während der Zeit, in der sie heruntergefahren sind, können auch einige kritische Anwendungen wie Datenbankserver, Nachrichtenwarteschlangen oder Backup-Jobs von der „hart“ Abschaltung betroffen sein.
Zusätzlich werden alle anderen vom Host bereitgestellten Dienste beendet. Wenn Ihr Host also Mitglied eines VSAN-Clusters ist, wirkt sich ein PSOD ebenfalls auf vSAN aus.
Der problematischste Aspekt eines PSOD ist, dass man dadurch das Vertrauen in seine Infrastruktur verliert, zumindest bis man der Sache auf den Grund geht. Ok, Sie können sich durch einen Neustart den Vertrauensverlust etwas mindern, haben möglicherweise High Availability (HA) oder sogar Fault Tolerance (FT), sodass die Auswirkungen vielleicht nicht verheerend sind… aber bis Sie die Grundursache nicht lösen, kann der Gedanke, dass dies wieder oder auf einem anderen Server passieren kann, Sie nachts wachhalten.
Was ist zu tun, wenn ein PSOD stattfindet?
1. Analysieren Sie die violette Bildschirmmeldung
Sobald Sie eine PSOD feststellen, ist es wichtig einen Screenshot zu machen Wenn Sie eine Fernverbindung (IMM, iLO, iDRAC,…) zur Konsole herstellen wird es einfach sein, einen Screenshot zu machen. Wenn Sie jedoch ins Rechenzentrum gehen müssen, wird empfohlen, mit dem Handy ein Bild vom Bildschirm zu machen, denn dieser Bildschirm zeigt noch nützliche Informationen über die Ursache des Absturzes.

2. Kontakt zum VMware-Support
Es ist ratsam den VMware-Support zu kontaktieren und in Anspruch zu nehmen, bevor Sie mit der weiteren Untersuchung und Fehlerbehebung beginnen. Parallel zu Ihrer Untersuchung kann dieser Sie bei der Durchführung der Ursachenanalyse (RCA) unterstützen.
3. Neustart des betroffenen ESXi-Hosts
Um den Server wiederherzustellen, müssen Sie ihn neu starten. Es wird auch graten, ihn im Wartungsmodus zu belassen, bis Sie den vollständigen RCA durchführen, die Ursache ermitteln und beheben. Wenn Sie ihn nicht im Wartungsmodus belassen können, sollten Sie zumindest Ihre DRS-Regeln so fein abstimmen, dass nur unwichtige VMs auf ihm laufen. So können bei einem weiteren PSOD-Treffer die Auswirkungen minimiert werden.
4. Den Kernspeicherauszug abrufen
Nachdem der Server hochgefahren ist, sollten Sie den Coredump abholen. Der Coredump (auch vmkernel-zdump genannt) ist eine Datei, die Protokolle mit detaillierteren Informationen enthält, als die auf dem Diagnosebildschirm angezeigt werden. Sie wird bei der weiteren Fehlersuche verwendet. Auch wenn die Ursache des Absturzes aus der PSOD-Meldung, die Sie in Schritt 1 analysiert haben, offensichtlich erscheinen mag, ist es ratsam, sie durch einen Blick auf die Protokolle des Coredumps zu bestätigen.
Je nach Ihrer Konfiguration können Sie den Coredump in einer dieser Formen haben:
a. Auf der Scratch-Partition
b. Als .dump file auf einem der Datenspeicher des Hosts
c. Als .dump file auf dem vCenter über den Netdump-Dienst
Der Coredump wird besonders wichtig, wenn die Konfiguration des Hosts nach einem PSOD automatisch zurückgesetzt werden soll. In diesem Fall sehen Sie die Meldung nicht auf dem Bildschirm.
Sie können das Dumpfile mit SCP aus dem ESXi-Host herauskopieren und es dann mit einem Texteditor öffnen. Dieser enthält den Inhalt des Speichers zum Zeitpunkt des Absturzes. Die ersten Teile enthalten die Meldungen, die Sie auf dem violetten Bildschirm gesehen haben. Die gesamte Datei kann vom VMware-Support angefordert werden, Sie aber können nur das kompaktere vmkernel-Protokoll extrahieren:
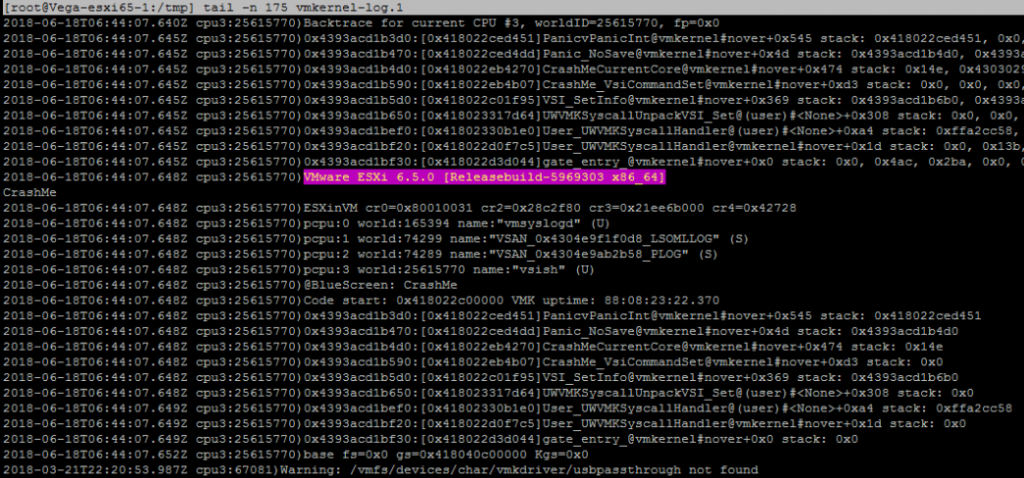
5. Entziffern Sie den Fehler
Bei der Fehlersuche und Ursachenanalyse kann man sich wie Sherlock Holmes fühlen. PSODs können sich manchmal in eine von Arthur Conan Doyle inspirierte Geschichte verwandeln: in den meisten Fällen ist es ein ziemlich geradliniger Prozess, bei dem es schwierig sein wird, das fünfte „Warum“ der 5-Whys-Technik zu ergründen.
Sie sollten mit der Fehlermeldung beginnen, die durch den Purple Screen of Death erzeugt wird. Glücklicherweise ist die Anzahl der erzeugbaren Fehlermeldungen begrenzt:
Exception Type 0 #DE: Divide Error
Exception Type 1 #DB: Debug Exception
Exception Type 2 NMI: Non-Maskable Interrupt
Exception Type 3 #BP: Breakpoint Exception
Exception Type 4 #OF: Overflow (INTO instruction)
Exception Type 5 #BR: Bounds check (BOUND instruction)
Exception Type 6 #UD: Invalid Opcode
Exception Type 7 #NM: Coprocessor not available
Exception Type 8 #DF: Double Fault
Exception Type 10 #TS: Invalid TSS
Exception Type 11 #NP: Segment Not Present
Exception Type 12 #SS: Stack Segment Fault
Exception Type 13 #GP: General Protection Fault
Exception Type 14 #PF: Page Fault
Exception Type 16 #MF: Coprocessor error
Exception Type 17 #AC: Alignment Check
Exception Type 18 #MC: Machine Check Exception
Exception Type 19 #XF: SIMD Floating-Point Exception
Exception Type 20-31: Reserved
Exception Type 32-255: User-defined (clock scheduler)
Da die Kernel-Panic von der CPU gesteuert wird, finden Sie weitere Informationen über diese Ausnahmen im Intel 64 und IA-32 Architekturen Software-Entwicklerhandbuch, Band 1: Grundlegende Architektur und Intel 64 und IA-32 Architekturen Software-Entwicklerhandbuch, Band 3A.
Die häufigsten Fälle werden in separaten VMware Knowledge-Base-Artikeln behandelt. Hier wird nur eine Referenztabelle solcher Fehler dargestellt, da die Artikel sehr detailliert und gut dokumentiert sind. Verwenden Sie diese Tabelle also als Index für die PSOD-Fehler:
6. Protokolle prüfen
Es kann vorkommen, dass die Ursache nicht sehr offensichtlich ist, wenn man sich die violette Bildschirmmeldung oder das Core-Dump-Protokoll ansieht. Somit fällt es schwer zu sagen, an welchem Ort als nächstes nach Hinweisen gesucht werden muss, in dem Host-Protokolle zu finden sind – insbesondere in dem Zeitintervall unmittelbar vor dem PSOD. Selbst wenn Sie das Gefühl haben, die Ursache gefunden zu haben, ist es ratsam, nicht sparsam zu sein und sie durch einen Blick in die Protokolle zu bestätigen.
Wenn Sie eine Unternehmensumgebung verwalten, haben Sie wahrscheinlich eine spezialisierte Protokollmanagementlösung zur Hand (wie VMware Log Insight oder SolarWinds LEM), sodass es einfach ist, diese Protokolle zu durchsuchen. Wenn Sie jedoch kein Protokollmanagement haben, können Sie sie leicht exportieren.
Die interessantesten Logdateien, die es zu erforschen gilt, wären:
| Components | Location | What is it |
| System messages | /var/log/syslog.log | Contains all general log messages and can be used for troubleshooting. |
| VMkernel | /var/log/vmkernel.log | Records activities related to virtual machines and ESXi. Most PSOD relevant entries will be in this log, so pay special attention to it. |
| ESXi host agent log | /var/log/hostd.log | Contains information about the agent that manages and configures the ESXi host and its virtual machines. |
| VMkernel warnings | /var/log/vmkwarning.log | Records activities related to virtual machines. Watch for heap exhaustion(Heap WorkHeap) related log entries. |
| vCenter agent log | /var/log/vpxa.log | Contains information about the agent that communicates with vCenter, so you can use it to spot tasks triggered by the vCenter and might have caused the PSOD. |
| Shell log | /var/log/shell.log | Contains a record of all commands typed, so you can correlate the PSOD to a command executed. |
Wie kann PSOD verhindert werden?
Die meisten softwarebezogenen PSODs werden durch Patches gelöst. Stellen Sie also sicher, dass Sie mit den neuesten Versionen auf dem Laufenden sind.
Vergewissern Sie sich, dass Ihre Server zusammen mit allen Geräten und Adaptern auf der Hardwarekompatibilitäts-Checkliste von VMware aufgeführt sind. Dies schützt vor einigen der unerwarteten hardwarebezogenen Probleme, stellt aber auch sicher, dass der VMware-Support in der Lage ist, Sie im Falle eines PSODs zu unterstützen.
Wie oben unter „Warum es passiert“ beschrieben, sind sich falsch verhaltende Treiber ebenfalls eine häufige Ursache für PSODs. Daher ist es unbedingt erforderlich, die Support-Websites der Hersteller regelmäßig auf aktualisierte Firmware und Treiber und insbesondere auf die dokumentierte PSOD zu überprüfen, damit die Treiber so schnell wie möglich durch ein Upgrade reagieren.
Bei Runecast analysieren wir regelmäßig die gesamte VMware Knowledge Base (kb.vmware.com), die aus mehr als 30.000 Artikeln besteht. Wir extrahieren aus den KBs umsetzbare Erkenntnisse, um virtualisierte Infrastrukturen proaktiv robuster, sicherer und effizienter zu machen. Wir sind mit der Purple Screen of Death sehr vertraut und in der Lage, die meisten Voraussetzungen zu identifizieren, die zu diesem Problem führen können. Durch die proaktive Analyse Ihrer Umgebung hilft Ihnen der Runecast Analyzer, von diesen Problemen abzulenken, sodass Sie die Gewissheit haben, dass die meisten PSODs, die in Ihrer Umgebung lauern, verhindert werden.
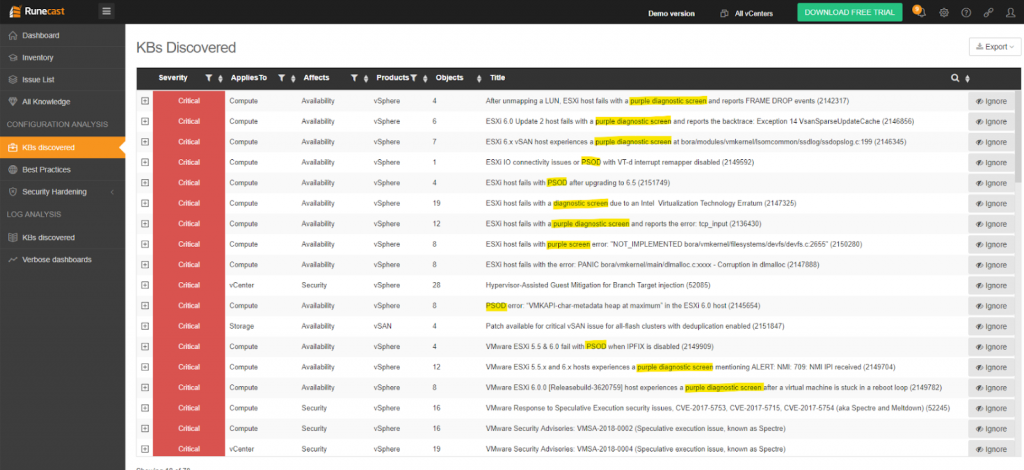
Quelle: Runecast BLOG
Sie haben Fragen zu weiteren Runecast Produkten?
Das Prianto EUCV Team hilft Ihnen gerne weiter. Informieren Sie sich auf der Prianto Website oder stellen Sie uns Ihre individuelle Anfrage.