Im folgenden Video erfahren Sie mehr über den Cohesity-Use Case „Security, Privacy & Compliance“. Lernen Sie, wie: rollenbasierte Zugriffssteuerung die

technical and business related background information about disruptive technologies in IT
Im folgenden Video erfahren Sie mehr über den Cohesity-Use Case „Security, Privacy & Compliance“. Lernen Sie, wie: rollenbasierte Zugriffssteuerung die

Im folgenden Video lernen Sie verschiedene Zugriffsmöglichkeiten (SMB, NFS, S3), wenn Cohesity als File-Server verwendet wird. Darüber hinaus erfahren Sie,

Cohesity DataProtect ist eine End-to-End-Datenschutzlösung, die vollständig auf der Cohesity DataPlatform konvergiert ist. DataProtect vereinfacht Ihre Datenschutzumgebung mit einer

Eine Plattform für Backup, Dateien, Objekte, Test/Dev, Cloud und Analytics Im Folgenden Video lernen Sie mehr über Cohesitys einzigartigen Ansatz im
Cohesity bietet die erste Storage-Plattform, die Datensicherung und Big-Data-Silos in einer grenzenlos skalierbaren Infrastruktur vereint Statt einer komplizierten, kostspieligen und
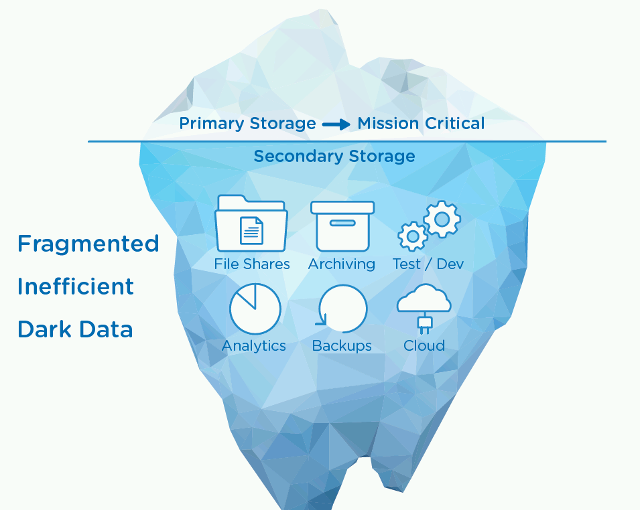
Die Mission von Cohesity ist es, den sekundären Speicher neu zu definieren. Herkömmliche Storage-Lösungen, wie zum Beispiel Dedupe-Appliances, Backup-Software und
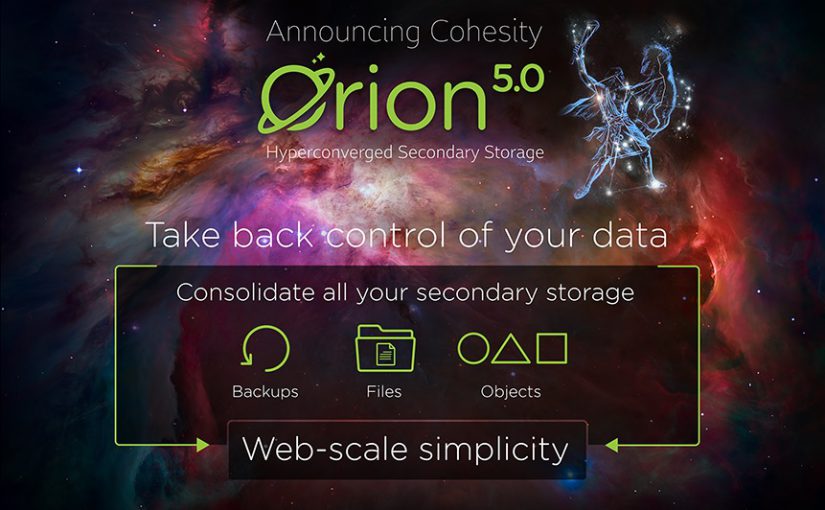
Cohesity, der Pionier des „Hyperconverged Secondary Storage“, hat kürzlich die neue Plattform Cohesity Orion 5.0 angekündigt, die voraussichtlich ab November

GDPR und Datenspeicherung Die EU General Data Protection Regulation (GDPR) ist die Regelung, um den Datenschutz für Bürger in der
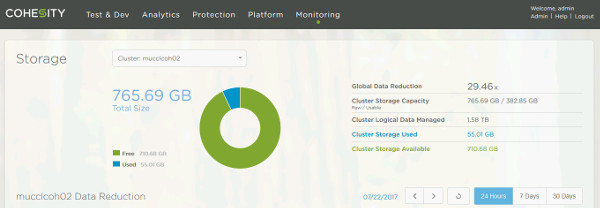
Exponentielles Datenwachstum und und ein ansteigender Bedarf an Private- und Hybrid-Cloud Storage bringen die objektbasierte Storage-Technologie in Richtung Mainstream. Anwendungen